Анатомия Фрагмента Google
Давайте разберем фрагмент кода Google во всей его красе - от строки «Сообщения / Авторы / Последнее сообщение», до даты документа, «Ключевые слова в контексте» («KWIC»), эллипсы, якорные ссылки внутри фрагмента.
Но прежде чем мы это сделаем, было бы неплохо определить термин « фрагмент» . Google определяет фрагмент как «описание или выдержка из веб-страницы», который следует за заголовком и предшествует URL-адресу и ссылке в кэше. Проще говоря, фрагмент относится к описательной части списка поиска Google. Он не включает заголовок и URL-адрес. Инженер Google Мэтт Каттс (Matt Cutts) дает хорошее представление об фрагментах и окрестностях в это видео ,
Это очень важная деталь: фрагменты определяются временем запроса; другими словами, они различаются в зависимости от ключевого слова, по которому выполняется поиск, как продемонстрировано в блоге Wordstream о контроле над фрагментами. Вот ,
Каковы компоненты фрагмента Google?
Во-первых, иногда есть серая строка текста, которая предшествует всему остальному. Если Google определяет что сайт является дискуссионным форумом, вы увидите серым текстом: «[число] сообщений - [число] авторов - последнее сообщение: [некоторая дата]», как показано в примере ниже:

Если это научная статья, то в сером тексте написано что-то вроде «J Smith - 2010» или «J Smith - Цитируется в 1 - Статьи по теме». Если в результате появится книга, то будет показано что-то вроде «J Smith». - 2010 - художественная литература - 333 страницы ». Если страница размечена микроформатами, серый текст может отображать структурированные данные о людях, местах, событиях, рейтингах / обзорах продуктов и т. Д. - это упоминается Google как богатый фрагмент .
Богатые фрагменты встречаются относительно редко, поэтому не ожидайте, что использование микроформатов автоматически вызовет расширенные фрагменты. Я ожидаю, что это изменится, поскольку Google продолжает внедрять их богатые фрагменты. Вместо того чтобы подробно обсуждать подробные фрагменты, я укажу статья на тему, написанную одним из моих коллег здесь, в Коварио, Джилл Кохер.
Затем он переключается на черный текст. Иногда фрагмент содержит дату в начале, за которой следуют эллипсы («…»). Это происходит, если Google определяет, что с рассматриваемой страницей связана первичная дата, как это часто бывает в сообщениях в блоге. Это не относится к страницам категорий блогов, поскольку в списке есть несколько сообщений с датой, связанной с каждым.
Google достаточно искусен в определении даты на странице. Это не должно быть отмечено специальным микроформатом. Я видел даты, заключенные в теги div или span с именем класса, которое не является стандартным (например, class = ”date”, class = ”submit”, class = ”posthead” и т. Д.). Я видел даты в тегах dd с меткой типа «Дата публикации» в теге dt или просто словами «Последнее изменение:» перед датой. Я даже видел даты просто голые в копии. Google правильно обработал их все.
Если даты нет, но фрагмент начинается с эллипсов, это означает, что фрагмент был извлечен из большего объема текста (будь то часть мета-описания или копии страницы - подробнее об этом через минуту) и текст, предшествующий эллипсам, был опущен. Точно так же, когда в конце фрагмента следуют эллипсы, фрагмент был укорочен по длине. Максимальная длина фрагмента (по крайней мере, стандартного фрагмента), не включая эллипсы в начале или конце, составляет 156 символов. Если источник фрагмента (например, мета-описание) длиннее 156 символов, фрагмент будет обрезан и эллипсы будут отображаться, чтобы отметить, где текст продолжается, но был пропущен в представлении фрагмента.
Эллипсы могут возникать в начале, и / или в конце, и / или где-то между ними один или несколько раз. Из этого правила из 156 символов есть исключение: иногда для определенных списков отображается расширенный фрагмент, например, когда это более эзотерический запрос. Или, когда листинг скрыт глубоко в результатах поиска, где фрагмент содержит 3 или даже 4 строки в результатах поиска вместо стандартных 2 строк, и, таким образом, число символов может почти удвоиться (как на скриншоте выше). .)
Как повлиять на текст фрагмента, чтобы использовать мета-описание
Копия в черном тексте может быть получена из одного или нескольких из этих источников: из мета-описания, из описания с сайта Открыть каталог список, из содержимого тела страницы, или даже их комбинации. Я видел случаи, когда мета-описание и копия тела были включены в сниппет.
Удивительно, но даже скрытый («display: none») текст может оказаться во фрагменте. Вместо того, чтобы оставлять свой фрагмент на волю случая, попробуйте «убедить» алгоритм Google использовать вместо этого ваше мета-описание (при условии, что оно хорошее, то есть хорошо написано и, конечно же, заставляет вас переходить по клику!) Путем включения популярных поисковых терминов в мета описание.
Скорее всего, мета-описание будет использоваться по умолчанию, когда страница не содержит поискового запроса пользователя и ранжируется в основном из-за входящих ссылок и их якорного текста. Вот (возможно, очевидный) совет: посмотрите в своей веб-аналитике главные поисковые термины, привлекающие трафик на страницу, и убедитесь, что эти термины присутствуют в мета-описании этой страницы.
Мета-описания лучше всего создавать вручную, но для большого сайта это, вероятно, нецелесообразно. К счастью, мета-описания, сгенерированные автоматически на основе рецепта, тоже могут сработать. Например, продавец может автоматически генерировать метаописания для своих страниц товара, в результате чего все ключевые биты информации, которые разбросаны по всей странице (например, цена, размер, стиль, производитель), будут собраны вместе - поскольку в противном случае маловероятно, что сгенерированный Google фрагмент будет собирать всю эту информацию.
В соответствии с это центральное сообщение блога Google для веб-мастеров Мета-описание будет использоваться с меньшей вероятностью, если автоматизированный алгоритм Google сочтет его низким качеством. Что может заставить Google считать мета-описание низкого качества? Если он состоит из длинных цепочек ключевых слов, дублирования информации, уже содержащейся в теге заголовка, дублирования контента в самом мета описании или плохого форматирования, что затрудняет чтение описания.
Список открытых каталогов, если он у вас есть, вероятно, превзойдет ваше мета-описание и копию страницы для вашей домашней страницы. Например, выполните поиск «starbucks», и вы увидите, что на домашней странице Starbucks.com есть фрагмент из одной строки: «Международная сеть. Предлагает магазин локатор, меню и информацию о продукте. »
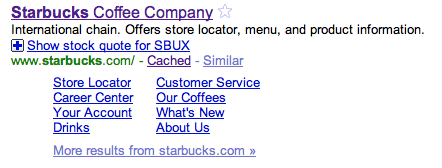
Это описание из списка Starbucks в открытом каталоге. Несмотря на то, что мета-описание («домашняя страница Starbucks.com») включает в себя поисковый термин (в данном случае «starbucks»), а описание ODP - нет, последнее является тем, что выбрано для фрагмента. Если вы не хотите, чтобы ваш список ODP был основой для вашего заголовка или фрагмента, используйте тег NOODP мета-роботов, как описано выше. Вот ,
Поиск фрагментов и «Ключевые слова в контексте»
В черном тексте вы часто будете видеть ключевые слова, выделенные жирным шрифтом. Слова, выделенные жирным шрифтом, соответствуют поисковым ключевым словам, введенным пользователем. Инженеры Google называют этот термин на информационно-поисковой (IR) терминологии как Ключевые слова в контексте чаще по аббревиатуре KWIC. Мэтт Каттс говорит о KWIC (произносится «быстро») в это видео ,
Google использует основание, морфологию и синонимы, чтобы связать ключевые слова поисковика с ключевыми словами в документе. Другой алгоритм герунда (-ing вместо -ed) может считаться совпадением алгоритмом релевантности Google, но он может или не может быть выделен как ключевое слово в контексте. Проводя свои собственные тесты, я обнаружил случаи, когда запросы в единственной форме возвращали множественные формы ключевых слов, выделенных жирным шрифтом, и наоборот.
Дополнительные функции сниппета
После строки (строк) черного текста может быть «плюс». Плюс может, например, быть с биржевой диаграммой для листинга домашней страницы публично торгуемой компании. Или карта соответствующего местоположения, если Google удалось извлечь основной адрес со страницы.
Дополнительные ссылки также могут присутствовать после черного текста. Ссылки на сайты традиционно не считаются частью сниппета. Ссылки в их стандартной форме указывают на другие местоположения на сайте, используя текст, полученный из якорного текста или тегов заголовка. Но теперь есть также ссылки ссылок на основе привязки, которые указывают на местоположения на той же странице (когда на странице присутствуют ссылки, содержащие #).
Дополнительные ссылки иногда будут присутствовать в самом фрагменте (читайте об этой функции «Перейти к»). Вот ). Самое странное, что ссылки на якорные сайты иногда прикрепляются к форумам, что подробно описано в конце эта почта , Ссылки сайта выходят за рамки этой статьи; Я сохраню это в другой раз. А пока проверь Эта статья от одного из моих коллег из Новой Зеландии, чтобы узнать больше о критериях Google для отображения ссылок сайта и о том, как влиять на то, когда и как они отображаются.
Иногда вы можете встретить список поиска без фрагмента. Это может произойти, если сайт переходит в автономный режим или недоступен, например, во время DDoS-атаки. Более вероятный сценарий, если страница была запрещена robots.txt. Директива Disallow сообщает роботу Google о том, что он не должен заходить на страницу, но он все равно может указывать ее в результатах поиска - даже если он не знает, что содержится на этой странице. С другой стороны, директива No-follow, которая также неофициально поддерживается Google, полностью исключит страницу из результатов поиска.
5 мифов о фрагментах Google
Я хотел бы воспользоваться моментом, чтобы развеять несколько мифов о фрагментах кода:
- Фрагмент фрагмента является синонимом списка поиска и поэтому включает заголовок, URL, ссылку в кэше и т. Д. Не правда. Google делает очень ясно тот факт, что термин сниппет применяется исключительно к описанию - и поэтому следует за заголовком и предшествует URL-адресу и ссылке в кэше.
- Google всегда использует мета-описание во фрагменте, если оно определено . Это далеко не так. Как уже упоминалось, фрагменты относятся к конкретному запросу и поэтому всегда меняются. Даже если ваше мета-описание включает в себя поисковый запрос, никаких гарантий нет.
- Мета-описания помогают с рейтингом, а не просто фрагмент. Это явно не соответствует действительности. Согласно Google, «хотя точные метаописания могут улучшить рейтинг кликов, они не повлияют на ваш рейтинг в результатах поиска» (от этот вышеупомянутый пост.)
- Ключевые слова в списке поиска выделены жирным шрифтом, поскольку они влияют на рейтинг . Нету. Выделение ключевых слов (KWIC) предназначено исключительно для удобства пользователей. Мета-описание, как уже указывалось выше, не влияет на рейтинг страницы.
- Максимальная длина стандартного фрагмента составляет 160 символов. Я видел различных SEO-блогеров, утверждающих максимальную длину 150, 156, 160, 161 и 165. Какой правильный ответ? Как уже упоминалось выше, 156.
Я люблю видеть творческие фрагменты. Вот один из моих любимых, с домашней страницы Даррена Слаттена (SEOmofo.com):

Говоря о Даррене, я призываю вас проверить эти умные эксперименты с фрагментами он провел и его Оптимизатор фрагментов инструмент. Еще один полезный инструмент - этот от Google - это Инструмент тестирования Rich Snippets ; просто не надейтесь на то, что это означает, что ваши списки будут отображаться с обильными фрагментами в ближайшее время - если, конечно, вы не размером с LinkedIn или Hulu.
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,
Об авторе
Похожие
Обновления алгоритма Google: краткая история улучшений SEO... google-kratkaa-istoria-ulucsenij-seo-1.jpg" alt="Если вы хотите, чтобы вас заметили в Интернете, то, несомненно, ваша главная цель - попасть в топ Google"> Если вы хотите, чтобы вас заметили в Интернете, то, несомненно, ваша главная цель - попасть в топ Google. Конечно, вы можете арендовать рекламное место с платой за клик в верхней части поисковой выдачи, но, в конечном счете, ваши долгосрочные цели будут достигнуты только при условии 6 инструментов Google, которые вам нужны для SEO
Независимо от того, являетесь ли вы контент-маркетологом, SEO или онлайн-маркетологом, наша индустрия имеет отношения любовь / ненависть с Google. Независимо от того, как вы это воспринимаете, у Google всегда есть выбор бесплатных инструментов, которые Мета-теги SEO: как анализирует Google
Сегодня я немного расскажу о метатегах и о том, как они интерпретируются Google. Многие миряне SEO они думают, что SEO - это всего лишь вопрос мета-тегов, и все идеально. Конечно, оптимизация также помогает, но SEO - это гораздо больше. Давайте отложим это в сторону и начнем, что имеет значение. Фрагмент - это текст, который появляется под ссылками в результатах поиска. То же самое построено на основе Что такое алгоритмы Google?
Если вы не отстаете от интернет-маркетинга или даже просто регулярно просматриваете информацию в Интернете, вы наверняка слышали об алгоритмах Google. Но задумывались ли вы когда-нибудь, кто они? Чтобы понять, что такое алгоритм Google, давайте сначала посмотрим, что такое алгоритмы в целом. Стандарт определение это: набор правил для решения задачи за конечное число шагов. На языке компьютеров алгоритм 10-минутное руководство Google по основам SEO
26 июня 2012 мин. Чтение От исследования ключевых слов до обратных ссылок, оставаясь на вершине поисковая оптимизация стратегии могут быть работой на полную ставку сами по себе. Google SERP Simulator: симуляция результатов поиска Google
... Google Preview (SERP) Метатеги Google для SEO, что на самом деле понимает Google?
Готовы узнать, какие метатеги на самом деле понимает Google? Вот так… Если вы даже отдаленно заинтересованы в ранжировании веб-страницы или сайта, то вы, вероятно, уже знаете о важности мета-тегов. Это теги, которые отображаются в разделе <head> документа HTML и содержат информацию о содержимом страницы. Их называют «мета», потому что они метаданные или данные о данных. Google Penguin 2.1: изменение нашей стратегии SEO
Недавно выпущенное Google обновление Penguin 2.1 застало SEO-сообщество врасплох. Мэтт Каттс сказал, что Penguin 2.1 затронет> 1% поисковых запросов, однако веб-мастера заметили значительное влияние этого обновления. После публикации Penguin 2.1 Органические против Платные списки в Google
Не смущайтесь, когда кто-то "гарантирует" размещение вашей первой страницы в Google. В этих ситуациях они либо используют неэтичные методы, либо просто помещают вас в раздел платных списков. Это весьма отличается от получения рейтинга первой страницы в обычных списках, что, как показали многочисленные исследования, составляет 70% трафика посетителей из поисковых систем. 4 бесплатных инструмента Google для повышения SEO вашей компании по ремонту компьютеров
Дэвид Молнар Специалистами по ремонту компьютеров являются специалисты по обслуживанию, консультанты и технические специалисты. Из-за этого важно также быть хорошими оптимизаторами. Хотя SEO меняется регулярно, есть несколько бесплатных инструментов, предназначенных для специалисты по ремонту компьютеров улучшить их SEO. С помощью этих инструментов вы можете получить высокий рейтинг в Google и стать Google публично обнародовал правила своей поисковой системы
... google-publicno-obnarodoval-pravila-svoej-poiskovoj-sistemy-1.jpg" alt="Если вы работаете на технологической сцене и не жили в безвыходном положении в течение последней недели, вы не могли избежать новостей на прошлой неделе о том, что Google предпринял беспрецедентный шаг по публичному раскрытию своей информации"> Если вы работаете на технологической сцене и не жили в безвыходном положении в течение последней недели, вы не могли избежать новостей на прошлой неделе о том, что Google предпринял Что может заставить Google считать мета-описание низкого качества?
165. Какой правильный ответ?
Но задумывались ли вы когда-нибудь, кто они?
Готовы узнать, какие метатеги на самом деле понимает Google?