Ваш Robots.txt Руководство для начинающих
Файл robots.txt представляет собой простой текстовый файл, который указывает, должен ли сканер иметь или не должен получать доступ к определенным папкам, подпапкам или страницам, а также к другой информации о вашем сайте. Файл использует Стандарт исключения роботов протокол, установленный в 1994 году для веб-сайтов для связи со сканерами и другими ботами. Абсолютно необходимо, чтобы вы использовали простой текстовый файл: Создание файла robots.txt использование HTML или текстового процессора будет включать в себя код, который сканеры поисковых систем будут игнорировать, если не умеют читать.
Как это работает?
Когда владелец сайта хочет дать какое-то руководство веб-сканерам, они помещают свой файл robots.txt в корневой каталог своего сайта, например https://www.example.com/robots.txt , Боты, которые следуют этому протоколу, извлекают и читают файл перед тем, как загружать любой другой файл с сайта. Если на сайте нет файла robots.txt, сканер предположит, что веб-мастер не хочет давать какие-либо конкретные инструкции, и продолжит сканирование всего сайта.
Robots.txt состоит из двух основных частей: User-agent и директив.
User-Agent
User-agent - это имя адресуемого паука, а в директивных строках содержатся инструкции для этого конкретного user-agent. Строка User-agent всегда идет перед строками директив в каждом наборе директив. Очень простой файл robots.txt выглядит так:
Пользователь-агент: Googlebot Disallow: /
Эти директивы предписывают пользовательскому агенту Googlebot, сканеру Google, держаться подальше от всего сервера - он не будет сканировать ни одну страницу на сайте. Если вы хотите дать инструкции нескольким роботам, создайте набор пользовательских агентов и запретите директивы для каждого из них.
Пользователь-агент: Googlebot Disallow: / Пользователь-агент: Bingbot Disallow: /
Теперь и пользовательские агенты Google, и Bing знают, как обходить весь сайт. Если вы хотите установить одинаковое требование для всех роботов, вы можете использовать так называемый подстановочный знак, обозначенный звездочкой (*). Поэтому, если вы хотите разрешить всем роботам сканировать весь ваш сайт, ваш файл robots.txt должен выглядеть следующим образом:
Пользователь-агент: * Disallow:
Стоит отметить, что поисковые системы будут выбирать наиболее конкретные директивы агента пользователя, которые они могут найти. Например, скажем, у вас есть четыре набора пользовательских агентов: один с использованием подстановочного знака (*), один для Googlebot, один для Googlebot-News и один для Bingbot, а ваш сайт посещает пользователь Googlebot-Images- агент. Этот бот будет следовать инструкциям для Googlebot, так как это самый специфический набор директив, применимых к нему.
Наиболее распространенными пользовательскими агентами поисковой системы являются:
Пользователь-агент Поисковая система Полевой baiduspider Baidu General baiduspider-image Baidu Images baiduspider-mobile Baidu Mobile baiduspider-news Baidu News baiduspider-video Baidu Видео bingbot Bing General msnbot Bing General msnbot-media Bing Изображения и видео adidxbot Bing Объявления Googlebot Googlebot Googlebot Google Image Google Images Googlebot-Mobile Google Mobile Googlebot-Новости Google News Googlebot-Video Google Video Mediapartners-Google Google AdSense AdsBot-Google Google AdWords не работает с Yahoo! Генерал яндекс яндекс генерал
запрещать
Вторая часть robots.txt - это строка запрета. Эта директива сообщает паукам, какие страницы им запрещено сканировать. В каждом наборе директив может быть несколько запрещенных строк, но только один пользовательский агент.
Вам не нужно указывать какое-либо значение для директивы disallow; Боты будут интерпретировать пустое значение disallow, чтобы означать, что вы ничего не запрещаете, и получите доступ ко всему сайту. Как мы упоминали ранее, если вы хотите запретить доступ ко всему сайту боту (или всем ботам), используйте косую черту (/).
Вы можете получить детализацию с помощью директив disallow, указав конкретные страницы, каталоги, подкаталоги и типы файлов. Чтобы заблокировать сканеры с определенной страницы, используйте относительную ссылку этой страницы в строке запрета:
Агент пользователя: * Disallow: /directory/page.html
Блокируйте доступ ко всем каталогам таким же образом:
Агент пользователя: * Disallow: / folder1 / Disallow: / folder2 /
Вы также можете использовать robots.txt, чтобы запретить роботам сканировать определенные типы файлов, используя подстановочный знак и тип файла в строке запрета:
Пользовательский агент: * Disallow: /*.ppt Disallow: /images/*.jpg Disallow: /duplicatecontent/copy*.html
Хотя протокол robots.txt технически не поддерживает использование подстановочных знаков, роботы поисковых систем могут распознавать и интерпретировать их. Таким образом, в приведенных выше директивах робот автоматически расширяет звездочку в соответствии с путем к имени файла. Например, он сможет выяснить, что www.example.com/presentations/slideshow.ppt и www.example.com/images/example.jpg не разрешены, в то время как www.example.com/presentations/slideshowtranscript.html isn ' т. Третий запрещает сканирование любого файла в каталоге / duplicatecontent /, который начинается с «copy» и заканчивается на «.html». Таким образом, эти страницы заблокированы:
- /duplicatecontent/copy.html
- /duplicatecontent/copy1.html
- /duplicatecontent/copy2.html
- /duplicatecontent/copy.html?id=1234
Тем не менее, он не будет запрещать любые экземпляры «copy.html», хранящиеся в другом каталоге или подкаталоге.
Одна из проблем, с которой вы можете столкнуться с файлом robots.txt, заключается в том, что некоторые URL-адреса содержат исключенные шаблоны в URL-адресах, которые мы на самом деле хотим сканировать. Из нашего более раннего примера Disallow: /images/*.jpg этот каталог может содержать файл с именем «description-of-.jpg.html». Эта страница не будет сканироваться, поскольку она соответствует шаблону исключения. Чтобы решить эту проблему, добавьте символ доллара ($), чтобы обозначить, что он представляет конец строки. Это скажет сканерам поисковых систем избегать только тех файлов, которые заканчиваются шаблоном исключения. Поэтому Disallow: /images/*.jpg$ блокирует только файлы, оканчивающиеся на «.jpg», в то же время разрешая файлы с «.jpg» в заголовке.
Разрешать
Иногда вы можете захотеть исключить каждый файл в каталоге, кроме одного. Вы можете сделать это трудным способом, написав строку запрета для каждого файла, кроме того, который вы хотите сканировать. Или вы можете использовать директиву Allow. Он работает почти так же, как и следовало ожидать: добавьте строку «Разрешить» в группу директив для пользовательского агента:
User-agent: * Разрешить: /folder/subfolder/file.html Disallow: / folder / subfolder /
Подстановочные знаки и правила сопоставления с образцом работают для директивы Allow так же, как и для Disallow.
Нестандартные директивы
Есть несколько других директив, которые вы можете использовать в файле robots.txt, которые не являются общепризнанными поисковыми системами. Одним из них является директива Host. Это признано Яндексом, самой популярной поисковой системой в России, и работает как решение www. Однако, как кажется, Яндекс является единственной крупной поисковой системой, которая поддерживает директиву Host, мы не рекомендуем использовать ее. Лучший способ справиться с разрешением www - это использовать 301 редирект.
Другая директива, поддерживаемая некоторыми поисковыми системами, это crawl-delay. Он задает числовое значение, которое представляет количество секунд - линия задержки сканирования должна выглядеть как задержка сканирования: 15. Она используется по-разному в Yahoo !, Bing и Yandex. Yahoo! и Bing использует это значение как время ожидания между действиями по сканированию, в то время как Яндекс будет использовать его как время ожидания для доступа к вашему сайту. Если у вас большой сайт, вы, вероятно, не хотите использовать эту директиву, поскольку она может серьезно ограничить количество просматриваемых страниц. Однако, если вы не получаете почти никакого трафика от этих поисковых систем, вы можете использовать crawl-delay для экономии пропускной способности.
Вы также можете установить задержку сканирования для определенных пользовательских агентов. Например, вы можете обнаружить, что ваш сайт часто сканируется с помощью инструментов SEO, которые могут замедлить ваш сайт. Вы также можете заблокировать их все вместе, если не чувствуете, что они вам помогают.
Наконец, вы можете использовать файл robots.txt, чтобы сообщить поисковым системам, где найти карту сайта, добавив строку Sitemap: в любом месте файла. Эта директива не зависит от пользовательского агента, поэтому боты смогут интерпретировать ее там, где вы ее поместите, но лучше поставить ее в конце, чтобы облегчить себе задачу. Создайте новую строку файла Sitemap для каждого имеющегося у вас файла Sitemap, включая ваши файлы Sitemap для изображений и видео или индексный файл Sitemap. Если вы предпочитаете, чтобы ваше местоположение на карте сайта было недоступно для всех, вы можете не указывать это и вместо этого отправлять карты сайта в поисковые системы напрямую.
Узнайте больше о том, как создать и оптимизировать XML-карту сайта. Вот ,
Почему вы хотите один?
Если поиск, индексация и ранжирование вашего сайта в результатах поисковой системы - это главное для SEO, зачем вам вообще исключать файлы на своем сайте? Есть несколько причин, по которым вы хотите заблокировать доступ ботов к разделам вашего сайта:
У вас есть личные папки, подпапки или файлы на вашем сайте - просто помните, что любой может прочитать ваш файл robots.txt, поэтому выделение местоположения частного файла с помощью директивы disallow откроет его для всего мира.
Блокируя менее важные страницы на вашем сайте, вы расставляете приоритеты в бюджете сканирования ботов. Это означает, что они будут тратить больше времени на сканирование и индексацию ваших самых важных страниц.
Если вы получаете большой трафик от других сканеров, которые не являются поисковыми системами (например, инструментами SEO), сэкономьте пропускную способность, запретив их пользовательским агентам.
Вы также можете использовать файл robots.txt, чтобы поисковые системы не индексировали дублирующийся контент. Если вы используете параметры URL, которые приводят к тому, что ваш сайт содержит один и тот же контент на нескольких страницах, используйте символы подстановки, чтобы исключить эти URL:
Агент пользователя: * Disallow: / *?
Это предотвратит доступ сканеров к любым страницам с вопросительными знаками в URL-адресе, что часто приводит к добавлению параметров. Это особенно полезно для сайтов электронной коммерции, которые имеют множество параметров URL, что приводит к тонне дублированного контента из-за фильтрации и сортировки товаров.
Рекомендуется блокировать доступ к вашему сайту во время редизайна или миграции, о чем мы подробно рассказали предварительно , Заблокируйте доступ ко всему новому сайту, чтобы он не связывался с дублирующимся контентом, что в будущем будет препятствовать его ранжированию.
Чтобы проверить, есть ли у вас проблемы с файлом robots.txt, откройте Google Search Console , Посмотрите в своем отчете "Статистика сканирования", чтобы убедиться, что количество просканированных страниц за день значительно сократилось; это может указывать на проблему с вашим файлом robots.txt.
Возможно, самая большая проблема с файлами robots.txt - это случайный запрет страниц, которые вы действительно хотите сканировать. Эту информацию можно найти в отчете об ошибках сканирования GSC. Проверьте страницы, которые возвращают код ответа 500. Этот код часто возвращается для страниц, заблокированных robots.txt.
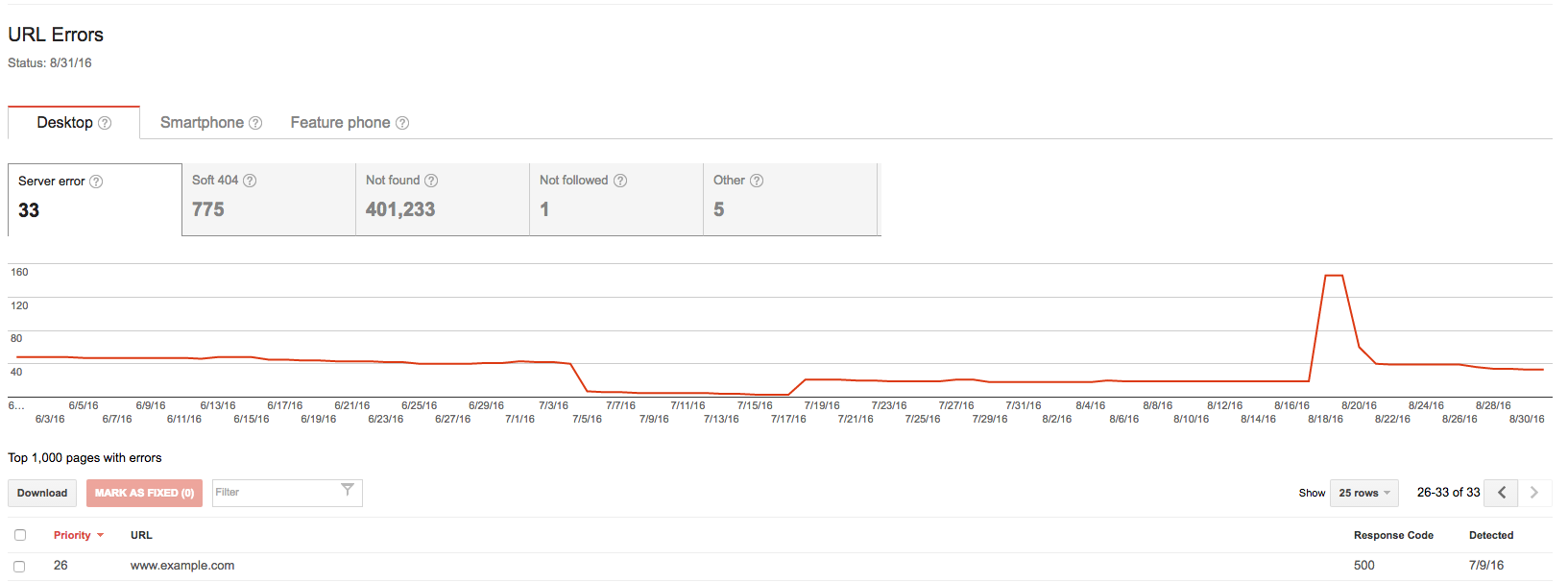
Проверьте все URL-адреса, которые возвращают код ошибки 500 в соответствии с вашими директивами disallow в файле robots.txt.
Некоторые другие распространенные проблемы с файлами robots.txt:
Случайное добавление косой черты в конце имени файла. Даже если ваш канонический URL-адрес может содержать косую черту, добавление его в конец строки в файле robots.txt заставит ботов интерпретировать его как каталог, а не файл, блокируя каждую страницу в папке. Дважды проверьте ваши запрещенные линии на наличие косых черт, которых там быть не должно.
Блокировка ресурсов, таких как коды CSS и JavaScript, с использованием robots.txt. Однако это повлияет на то, как поисковые системы увидят вашу страницу. Некоторое время назад Google заявил, что запрещает CSS и Javascript будет рассчитывать против вашего SEO , Google может прочитать ваш код CSS и JS и использовать его, чтобы сделать выводы о вашем сайте. Когда он видит заблокированные ресурсы, подобные этому, он не может правильно отобразить вашу страницу, что удержит вас от рейтинга так высоко, как вы могли бы иначе.
Использование более одной директивы User-agent на строку. Поисковые системы игнорируют директивы, включающие в себя более одного пользовательского агента в строке, что может привести к неправильному сканированию вашего сайта.
Неправильная капитализация каталогов, подкаталогов и имен файлов. Хотя фактические директивы, используемые в robots.txt, не чувствительны к регистру, их значения. Поэтому поисковые системы видят Disallow: page.html, Disallow: Page.html и Disallow: page.HTML в виде трех отдельных файлов. Если ваш файл robots.txt содержит директивы для Page.html, но ваш канонический URL-адрес указан строчными буквами, эта страница будет просканирована.
Использование директивы Noindex. В SEO малоизвестный секрет, что вы можете использовать директиву noindex в файле robots.txt. Однако в прошлом году Джон Мюллер заявил, что вам следует избегать использования noindex в вашем файле robots.txt , Так что следуйте лучшей практике и придерживайтесь запретов и разрешайте директивы.
Противоречие с вашей картой сайта в вашем файле robots.txt. Скорее всего, это произойдет, если вы используете различные инструменты для создания файлов sitemap и robots.txt. Противоречить себя перед поисковыми системами всегда плохая идея. К счастью, это довольно легко найти и исправить. Отправьте и сканируйте свою карту сайта через GSC. Он предоставит вам список ошибок, которые вы затем сможете проверить в файле robots.txt, чтобы убедиться, что вы его там исключили.

- Запрет страниц в вашем файле robots.txt, которые используют метатег noindex. Сканеры, заблокированные от доступа к странице, не смогут видеть тег noindex, который может привести к тому, что ваша страница появится в результатах поиска, если она связана с другой страницей.
Также часто приходится бороться с синтаксисом robots.txt, особенно если у вас мало технических знаний. Одно из решений - попросить кого-то, кто знаком с протоколом роботов, просмотреть ваш файл на наличие синтаксических ошибок. Другой, и, вероятно, лучший вариант, это пойти прямо в Google для тестирования. Откройте тестер в консоли поиска Google, вставьте файл robots.txt и нажмите «Тест». Что здесь действительно удобно, так это то, что он не только обнаружит ошибки в вашем файле, но вы также сможете увидеть, запрещаете ли вы страницы, проиндексированные Google.
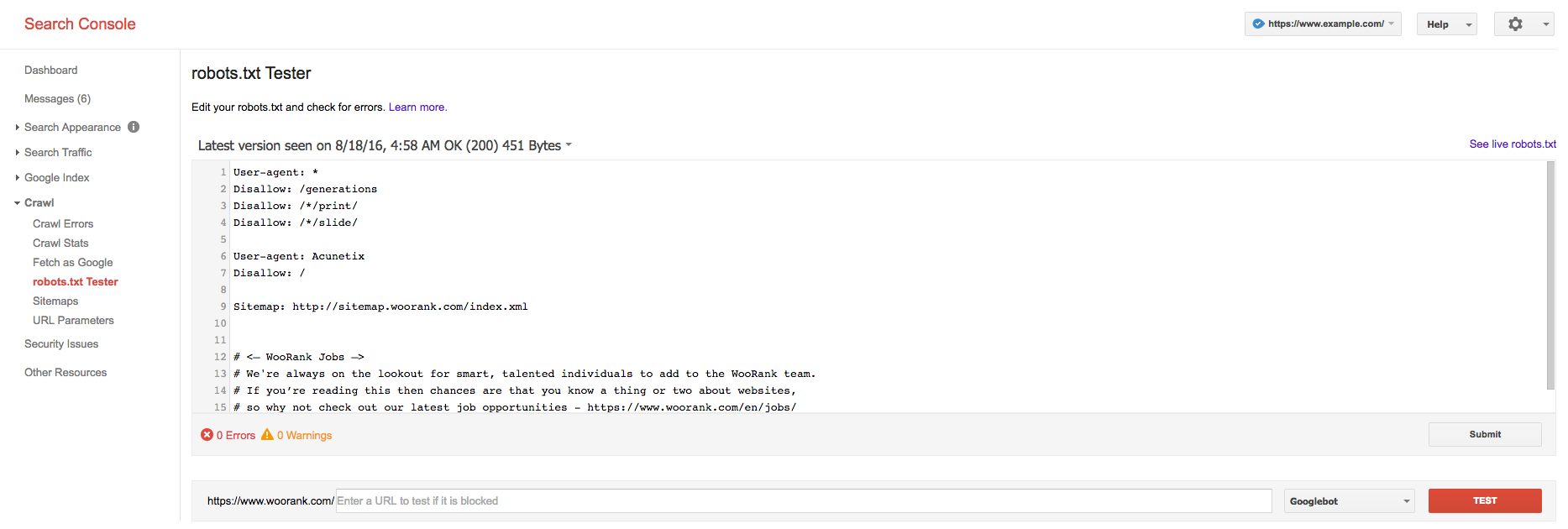
При создании или изменении файла robots.txt вы действительно должны тщательно протестировать его с помощью этого инструмента. Добавление файла robots.txt с ошибками, вероятно, серьезно повлияет на способность вашего сайта сканироваться и индексироваться, что может привести к тому, что он выпадет из рейтинга поиска. Вы можете даже заблокировать весь ваш сайт от появления в результатах поиска!
Правильно ли реализован ваш файл robots.txt? Аудит вашего сайта с помощью WooRank чтобы убедиться, что вы оптимизированы по 70+ критериям, в том числе на странице, технические и местные факторы.
Похожие
Что это такое и как работает Majestic?Специалисты по медиа, маркетингу и интернету используют величавый , Способность адаптироваться к широкому спектру рынков позволила этому инструменту онлайн-маркетинга позиционировать себя как один из самых популярных. Для профессионалов SEO он предлагает помощь в поиске потенциальных клиентов и управлении ими, подготовке предложений, отчетов и проверке веб-сайтов. Это позволяет аналитикам наблюдать за тем, что находится внутри и снаружи виртуального Вот как это работает с Google Images
Поиск картинок » Google картинки «Обсуждается (если даже разрешено показывать эскизы изображений, что за слабое…) - но для некоторых сайтов источник постоянного трафика. Вот мои выводы о том, на чем основан алгоритм поиска изображений. Как оптимизировать файл WordPress Robots.txt для SEO
2 Оптимизируйте Robots.txt для WordPress : Вы когда-нибудь слышали о Robots.txt ? Конечно, вы имели. Файл WordPress robots.txt жизненно важен для эффективности SEO сайта. Это сильно влияет на рейтинг сайта в поисковых системах. Это помогает поисковым системам знать, какую часть они должны индексировать, а какую - нет. Отсутствие файла robot.txt не мешает поисковым системам сканировать и индексировать ваш сайт, но иногда вам нужно блокировать Как работает SEO
SEO включает в себя много переменных. Прочитайте, как мы находим ваш идеальный баланс. Правильная смесь переменных необходима для построения вашего бренда и расширения клиентской базы. Как именно работает SEO? С высокого уровня это делается через два процесса. Оптимизация на странице Вне страницы оптимизации Первый процесс происходит внутри самого вашего сайта (оптимизация Каковы наиболее распространенные проблемы SEO по данным аудита за 3 года
Недавно мы поняли, что у нас есть доступ к свалке ценных SEO-данных на странице, поэтому мы начали копать. Затем мы выпустили наш изучить анализ SEO вопросов на странице , SEO на странице - это код и слова на вашем веб-сайте, которые влияют на рейтинг ваших страниц в результатах поиска. С начала 2013 года до середины 2015 года маркетологи развернули Raven's МЕСТНОЕ SEO
SEO-стратегия на основе определения местоположения - это новый маркетинговый стандарт. Каждый день все больше и больше людей на мобильных и настольных устройствах ищут местные предприятия, местные службы, локальные местоположения и локальную информацию. Поисковая оптимизация на основе местоположения (SEO) может помочь вам органично выделиться над завершением. В Kirk мы стремимся помочь нашим местным компаниям привлечь Что такое SEO и почему это важно?
Хотите знать, что значит SEO и как это может помочь вашему бизнесу? Обеспокоены, у вас нет навыков или бюджета, необходимых для начала? SEO является доступным и эффективным, что позволяет вам привлечь новых клиентов и увеличить продажи. Давайте углубимся в SEO и как это может принести пользу вашему бизнесу. Что такое SEO? SEO, или поисковая оптимизация, означает настройку вашего сайта и контента для отображения Что такое отрицательный SEO? | Кто-то может навредить моему поисковому рейтингу?
Я много говорил о SEO в течение 4+ лет этого блога. Одна вещь, на которую я не смог пролить свет - это негативное SEO. Это будет очень короткий пост о негативном SEO, но вы можете читать дальше в Моз , Что такое отрицательный SEO? Black Hat SEO - почему вы не хотите туда идти
Серьезно, вы не хотите туда В настоящее время большинство маркетологов знают, что Black Hat SEO не очень хорошая вещь. И тем не менее, каждый год Google принимает меры против тысяч, если не миллионов, людей, которые следуют этой хитрой практике. Если вы почувствовали искушение присоединиться к темному миру Black Hat SEO, я, безусловно, понимаю ваше отчаяние. Иногда то, что считается «простым» способом привлечь больше внимания на сайте, может показаться Мета-теги SEO: как анализирует Google
Сегодня я немного расскажу о метатегах и о том, как они интерпретируются Google. Многие миряне SEO они думают, что SEO - это всего лишь вопрос мета-тегов, и все идеально. Конечно, оптимизация также помогает, но SEO - это гораздо больше. Давайте отложим это в сторону и начнем, что имеет значение. Фрагмент - это текст, который появляется под ссылками в результатах поиска. То же самое построено на основе Как улучшить SEO в Blogger
Вести блог, особенно в Blogger, довольно легко, и с развитием технологий он становится все более интуитивным и графическим, требующим все меньше технических знаний. Как мы продемонстрировали пошагово в предыдущем посте, создание блога занимает чуть более 1 минуты (если у вас сверхбыстрое соединение, это, вероятно, займет меньше времени), и его управление также очень доступно. Однако, хотя ваш блог автоматически и по умолчанию доступен для всех, это не означает, что люди
Комментарии
Вы изо всех сил пытаетесь получить результаты, которые вы хотите от ведения блога?Вы изо всех сил пытаетесь получить результаты, которые вы хотите от ведения блога? Хотите знать, имеет ли это смысл для вашего бизнеса? Неужели вся эта история с блогами начинает ощущаться гигантской тратой времени? Если вы ответили «да» на любой из этих вопросов, важно, чтобы вы поняли два ключевых момента: Важно не сдаваться слишком рано в блогах. Игра сильно изменилась за последние несколько лет. Отказ от слишком Если вы пострадали, как вы можете понять, почему?
Если вы пострадали, как вы можете понять, почему? Это будет почти невозможно полностью понять; нет только одного алгоритма, и ни один алгоритм полностью не известен сообществу SEO. Некоторые алгоритмы понятны лучше, чем другие, и сообщество SEO определило ключевые составляющие подтвержденных алгоритмов, которые помогают клиентам и брендам оптимизироваться (например, Panda; мы знаем, что это фокусируется на обесценивании тонкого контента, дублированного контента и / или контент, который Вы можете подумать, что это ценно, но спрашивали ли вы своих посетителей, действительно ли это ценно?
Вы можете подумать, что это ценно, но спрашивали ли вы своих посетителей, действительно ли это ценно? Если они не предпримут действия, оно может оказаться не таким ценным, как вы ожидали. Или, возможно, ваш язык конверсии не сформулирован правильно, чтобы объяснить ценность. Попробуйте A / B проверить формулировку вокруг ваших точек конверсии, чтобы увидеть, является ли это просто проблемой коммуникации. Как только ваши посетители попадают в форму или на кассу, все ненужные Так как вы действительно угощаете потребителя Pinoy - почему вы выбрали бы иностранного поставщика SEO?
Так как вы действительно угощаете потребителя Pinoy - почему вы выбрали бы иностранного поставщика SEO? Итог: выбор правильной компании SEO зависит от различных факторов. Нет единого элемента, на котором вам нужно сосредоточиться, а лучше взять разные характеристики и сравнить их друг с другом. Только благодаря тщательному анализу вы сможете найти лучшую компанию SEO, которая сможет удовлетворить ваши потребности. [ВЫЯВЛЕНО] 101 SEO-стратегия на Филиппинах Вы знаете, как, когда вы что-то гуглите, вы получаете список сайтов?
Вы знаете, как, когда вы что-то гуглите, вы получаете список сайтов? Ну, один из способов, чтобы ваш сайт появился в этом списке, это сосредоточиться на SEO. Приоритизация SEO - один из самых эффективных способов убедиться, что ваш сайт работает наилучшим образом. Есть два основных аспекта: SEO на странице и SEO вне страницы. SEO на странице Качество контента. Чтобы обеспечить ценность SEO, контент должен быть хорошо Как мы можем убедиться, что наша платная реклама работает так, как она должна быть?
Как мы можем убедиться, что наша платная реклама работает так, как она должна быть? Есть несколько простых вещей, которые мы можем сделать, чтобы убедиться, что мы получаем максимальную отдачу от нашего доллара. Понять, как долго работают ключевые слова Tail Прежде чем перейти к платной рекламе (особенно поисковой рекламе), нам нужно понять, как все это работает, в частности, как работают ключевые слова. Инструмент Google AdWords Как вы можете добиться лучших результатов, чем вы?
Как вы можете добиться лучших результатов, чем вы? Какое поисковое намерение стоит за этими поисковыми запросами? Конечно, не стоит копировать все 1: 1, что вы узнаете при поиске. Тем не менее, вы можете быть очень вдохновляющим, чтобы сделать его лучше, чтобы сделать его более красивым или действительно пролить свет на все аспекты темы. эксперт наконечник 80% всех поисковых запросов являются информационными поисковыми запросами. Вы не уверены, как должен выглядеть ваш заголовок?
Вы не уверены, как должен выглядеть ваш заголовок? Тогда используйте рекламу AdWords в качестве вдохновения. Но помните, вы должны вдохновляться лучшим - и даже лучше! Совет → Поиск иностранных сайтов в той же отрасли, что и у вас, и посмотреть, что они делают. И избегайте стандартных слов, таких как «Добро пожаловать» и «Дом». Мы редко ищем веб-сайт, где мы используем ключевое слово «добро пожаловать» Тег title <title> НЕ совпадает с мета title <meta name = Как это работает?
Как это работает? Ну, поисковые роботы Google ползают по вашему сайту в поисках индикаторов вашего контента. Они ищут ключевые слова и расположение этих слов, они смотрят на то, на что ваш контент ссылается как внутри, так и снаружи, и они смотрят на ваше название и мета описание. Все это дает им больше информации, которую они могут использовать для определения вашего рейтинга. Если у вас есть все, что они ищут, вы неизбежно станете выше. Если у вас нет таких вещей, вы оставляете это Как вы себе это представляете?
Как вы себе это представляете? В соответствии с чешским законодательством у меня есть законные требования. В его финансовой концепции они незначительны. Петра Парубкова обвиняет Йиржи Парубека в домашнем насилии. Он бред. Об этом она сказала в интервью Lightning в августе 2018 Как вы можете сказать, если вы должны нанять местную компанию SEO?
Как вы можете сказать, если вы должны нанять местную компанию SEO? Если ваш бизнес соответствует какому-либо из перечисленных ниже условий, вам нужен местный SEO. У вас есть местная компания У вас есть компания с конкретными зонами обслуживания Вы являетесь франчайзи или владельцем франшизы Вам нужно больше трафика, потенциальных клиентов и продаж в специально отведенных для этого зонах рынка (DMA) Вы хотите укрепить свои списки через
Как это работает?
Как это работает?
Html?
Если поиск, индексация и ранжирование вашего сайта в результатах поисковой системы - это главное для SEO, зачем вам вообще исключать файлы на своем сайте?
Txt?
Txt ?
Как именно работает SEO?
Хотите знать, что значит SEO и как это может помочь вашему бизнесу?
Обеспокоены, у вас нет навыков или бюджета, необходимых для начала?
Что такое SEO?